Multi-tenant AI architecture explained
How to build AI that serves many customers without leaking data between them. Tenant isolation in the retrieval layer, the model layer, and the audit layer.
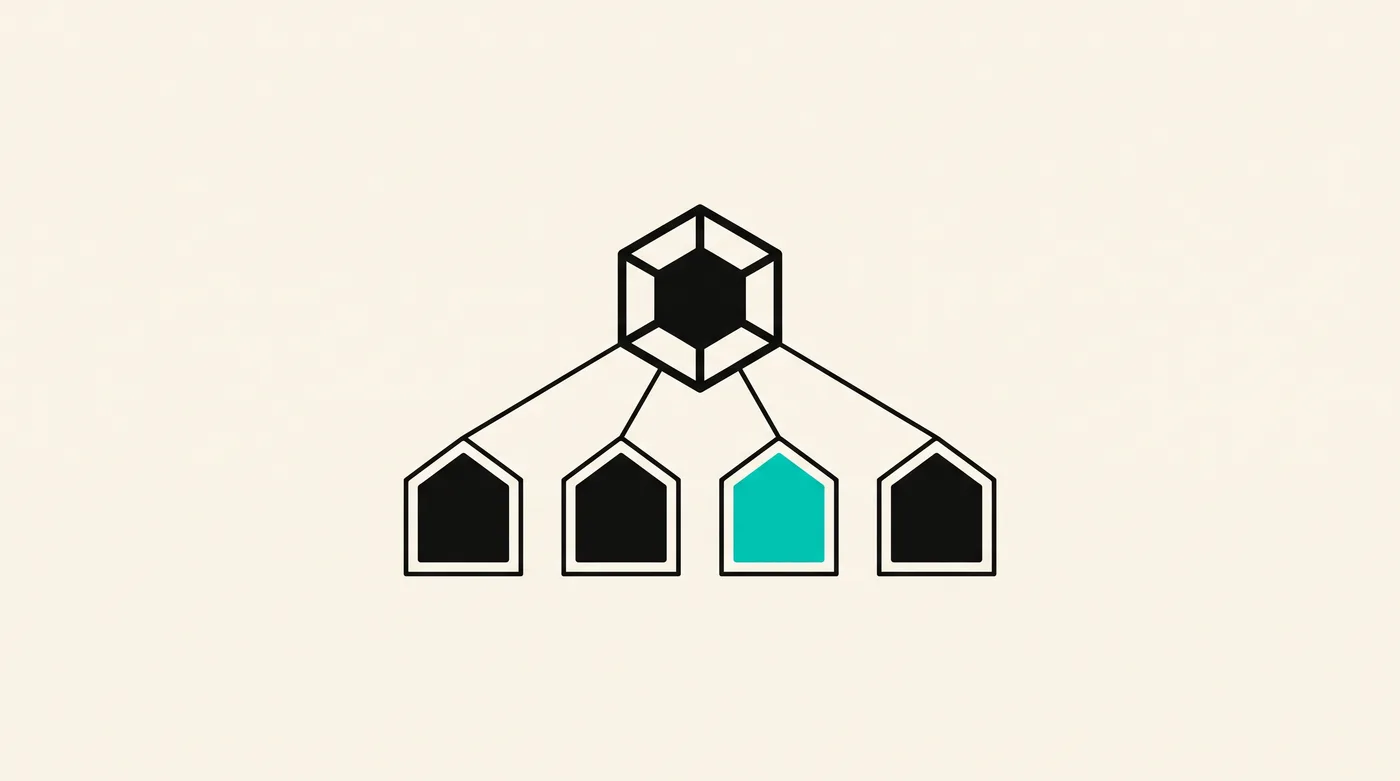
- Multi-tenant AI is harder than multi-tenant SaaS — there are three places data can cross tenants, not one.
- Isolation has to live in the retrieval layer, the model layer, and the audit layer. Skip any one and you have a leak.
- Per-tenant embeddings stores and per-tenant prompts are not enough on their own. The orchestration layer must enforce scope on every call.
- Three patterns that work in production. One pattern (shared fine-tunes across tenants) that should never ship.
Most AI products are demos for one user. Production AI products serve many. The leap between the two is harder than people expect — because AI has more places data can leak than a regular SaaS app does.
Below is the working frame we use building the XWorks Suite, which is multi-tenant by definition: every salon, every gym, every CA firm gets the same engine but cannot see another tenant's data.
The three isolation surfaces
1. The retrieval layer
When the AI looks up information to answer a question, where does it look?
If a customer support agent for "Acme Corp" can retrieve documents from "Beta Inc," you have a leak. The retrieval system needs to enforce tenant scope at the query level — every search is filtered by tenant ID before the AI sees results.
Patterns that work:
- Per-tenant vector stores. Each tenant gets their own embeddings namespace. Cleanest. Most expensive at scale.
- Shared vector store with tenant-id metadata + mandatory filter. Cheaper. Requires discipline — every query must include the filter, or you leak.
- Per-row ACL on retrieved documents. Even with the right tenant, only documents the current user is authorised for show up.
Patterns that fail:
- Filtering at the application layer after retrieval. The retrieval call already saw cross-tenant data. The model's behaviour can be subtly influenced even if you filter the visible output.
- Trusting the LLM to filter. Telling the model "do not show data from other tenants" in the prompt is not enforcement; it is a suggestion the model can ignore.
2. The model layer
If you fine-tune a model on customer data, whose data goes in?
A single fine-tune on combined data from all tenants is a leak by construction. Whatever the model learned from Tenant A is now visible to Tenant B. This is the pattern that should never ship.
Patterns that work:
- No fine-tuning on customer data. Use RAG for tenant-specific context, foundation model for general capability. Easiest to reason about. See what is RAG.
- Per-tenant fine-tunes. Each tenant gets their own fine-tuned model. Expensive. Clean.
- Adapter layers per tenant. LoRA / similar — a small per-tenant delta on top of a shared base model. Compromise between cost and isolation.
3. The audit layer
Who can see what the AI did?
The audit log is data. If a tenant's admin can see the AI's logs across tenants, you have a leak. If your support engineers can read every tenant's AI conversations to debug, you have a privacy problem.
Patterns that work:
- Per-tenant audit log storage. Tenants own their logs; Xwits operators can query only with explicit consent + an audit record of their access.
- Encryption-at-rest with per-tenant keys. Even if storage is shared, no operator sees plaintext without the tenant's key release.
- Redaction on operator access. Engineers debug on redacted logs by default; full plaintext access is a permissioned escalation.
The orchestration layer
Even if all three layers are isolated, the orchestration code can still leak — the code that wires together retrieval, model, and tools. The pattern that works:
- Every request enters with a verified
tenantId. tenantIdis passed to every downstream call: retrieval filter, prompt context, tool authorisation, audit log write.- The code path that calls a downstream service without
tenantIdfails closed at compile time, not at runtime. Type system enforcement. - Cross-tenant calls require a special privileged path that is audited and rate-limited.
What about prompt injection?
Multi-tenancy compounds prompt injection risk. An attacker in Tenant A's data who successfully injects into the AI could try to read Tenant B's data — through the AI's privilege.
The defence: the AI's effective capabilities are bounded by the current user's scope, not just the current tenant's. If a junior employee at Tenant A interacts with the AI, the AI cannot access data the junior cannot access, regardless of what the prompt says.
See prompt injection explained.
The shared fine-tune anti-pattern
The most common architectural mistake we see: a startup with five customers fine-tunes one model on all five customers' data, ships it as the platform model. Six months later, the customers ask "is my data being used to improve the model that serves my competitor?" The honest answer is yes.
The product is now uninvestable from a compliance standpoint. The fix is a full architectural reset.
Do not start there.
What to verify before signing a multi-tenant AI vendor
- Where do my embeddings live? Are they isolated per tenant?
- Is my data used to train models that serve other tenants? Get this in writing.
- Can your engineers read my AI logs without my consent? What is the access process?
- Show me the request flow: what data flows where on a typical AI call?
- If I export my data and leave, what stays behind?
See AI vendor evaluation framework for the full 15-criterion scorecard.
What this means for you
- Multi-tenant AI has three isolation surfaces. Skip any one and you leak.
- Never train one model on combined customer data. Even if it works technically, it kills you on compliance.
- Enforce tenant scope in code, not in the prompt. The prompt is a suggestion; the code is the fence.
- Audit-log access is privacy-sensitive. Engineers debug on redacted logs by default.
- Read our production AI properties for the broader checklist.
Designing a multi-tenant AI product? Book a 30-minute call. We will walk through your specific isolation model with you.
Related from the blog

The 5 properties of production AI (vs demo AI)
Demo AI wows you in fifteen minutes. Production AI runs for a year without breaking. Five properties that separate them — and a checklist before you ship.
What is RAG? A practical guide for AI builders
Retrieval-augmented generation, explained without the marketing fog. What RAG is, how it works, when it wins, and where it fails. From the team building AI products on it daily.

Why prompt injection matters more than you think
Prompt injection is the SQL injection of the AI era. We explain the attack, why guardrails alone do not solve it, and the architectural patterns that defend.
Talk to a real engineer.
A 30-minute call. We will tell you honestly whether AI is the right fix and what it would take.